打开微信,使用扫一扫进入页面后,点击右上角菜单,
点击“发送给朋友”或“分享到朋友圈”完成分享
Cambricon Pytorch应用实战——基于resnet50的训练和推理
系统介绍Cambricon Pytorch与原生Pytorch的区别和联系以及如何适配原生Pytorch,并且现场演练resnet50的训练和推理实践技术
Cambricon Pytorch应用【FAQ合集】
Q1: MM Detection框架训练的模型可以直接转成离线模型吗,有简便方法吗?
A1: 可以,生成离线模型需要使用magicmind推理引擎。
Q2: MLU270可以用GPU2MLU.py脚本吗?
A2: 目前MLU270系列不支持,MLU300系列为训推一体加速卡,支持该脚本。
Q3: 新算法算子开发有样例吗?
A3: BANG实战课中有具体讲解。
Q4: MLU300系列,支持VIT模型吗?
A4: 支持,后续VIT模型会开放到gitee上,点击链接:modelzoo: Cambricon Modelzoo (gitee.com)
Q6: 请问使用MLU训练出来的模型的通用性怎么样?
A6: 通用性很好,和GPU训练出来的一样。
Q7: 可否详细讲讲MLU- 技术?
A7: 后续分布式相关的课程展开介绍。
Q9: jit.trace之后,推理用的是magicmind后端吗?
A9: 是的。
Q10: jit模式是否支持可变推理?
A10: 支持 在配置参数时变动即可。
Q11: MagicMind支持训练吗?
A11: MagicMind是星空体育推出的推理加速引擎,是用来部署的,不支持训练。
Q14: 逐层和融合推理在精度上有差别?
A14: 没有精度的差别,可以具体观看本节视频课的实战环节,点击链接:【MLU370系列开发实战直播课】Cambricon Pytorch应用实战_哔哩哔哩_bilibili
Q15: 支持yolov5的训练吗?
A15: 支持 星空体育gitee上新了很多可供参考和一键运行的模型,点击链接:modelzoo: Cambricon Modelzoo (gitee.com)
Q16: Magicmind的模型可以快速部署吗?
A16: 可以通过python,c++的API进行快速部署。
Q17: MLU训练支持多机多卡吗?
A17: 支持,后续课程会讲到分布式训练。
Q18: 星空体育的PyTorch是否支持自定义算子?
A18: 支持。
Q19: BANG语言和C/C++有什么区别啊? 上手难吗? 请问可以在哪试用?
A19: 是类C的编程语言,有C语言和cuda基础上手不难。开发者社区有试用申请。
Q20: Pytorch 支持什么版本?
A20: 目前支持PyTorch 1.6和1.9版本。
Q21: patch的代码是需要编译后才可以使用的吗?
A21: 是的。
Q22:请问3系列加速卡支持哪些计算精度类型?
A22: MLU370系列支持FP32、FP16、INT16、INT8等,具体规格点击官网查看:思元370系列 - 星空体育 ()
Q23: 请问分发的最小粒度是按算子吗?有没有按子图的?
A23: 一般来说是按算子粒度来分发。
Q24: magicmind的推理性能通常比cnnl更好是吗?
A24: 是的,使用了诸多融合、优化技术。
Q25: 训练是否可以使用jit模式?
A25: 不支持。
Q26: 如果推理遇到不支持的算子,怎么办?
A26: 可以通过做算子拼接、算子开发并PlugIn,或提到星空体育社区反馈。
Q27: 星空体育的pytroch是否支持自定义算子?
A27: 支持。
Q28: 星空体育370的MLU 的原理是什么?
A28: MLU 涉及分布式、多机多卡以及单机多卡的互联,在思元370应对多卡多芯并行任务时,提供更高效的并行效率。
Q30: gpu移植到mlu需要改动哪些?
A30: 主要是修改设备相关的改动,或者使用星空体育提供的脚本工具。可以参考下图总结:
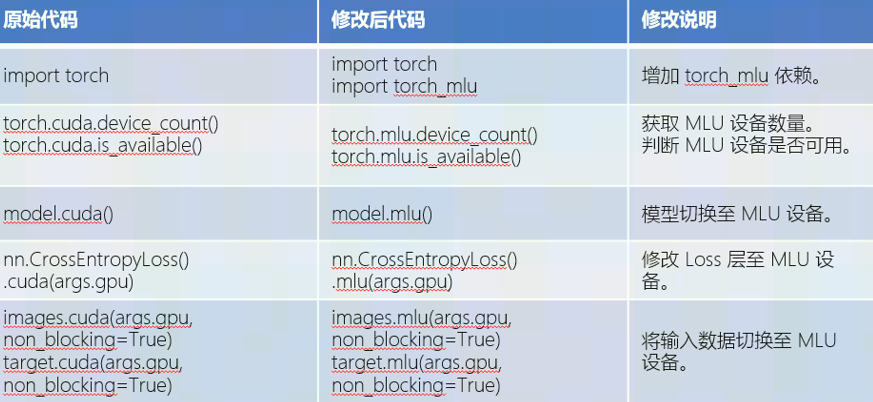
Q31: 使用torch_gpu2mlu.py这个脚本是不是就不用人工修改原生代码就可以移植到mlu了?
A31: 是的,理论上不需要人工修改了。
Q32: gpu2mlu.py,请问在哪里下载呢?
A32: 后续开放下载的软件栈中会带有。
Q33: 星空体育SDK里转换工具是要对整个代码工程进行作用吗?还是只需要对训练入口文件?
A33: 对整个工程作用。
Q34: 用mlu进行单机多卡训练和单机单卡的训练有啥大的差别吗?
A34: 单机多卡的训练速度更快,接口上会有少许不同。关于分布式训练后续课程会介绍。
Q35: cnnl方式和融合方式做前向推理,精度会有差别吗?
A35: 没有差别。
Q36: 可以做量化推理吗?流程是怎样的?
A36: 支持量化,后续课程会讲到量化的使用。
Q37: trace之后,推理走的是magicmind后端吗?
A37: 是的。
Q38: 当前是否支持与GPU混插进行多卡异构训练?分别推理部署呢?
A38: 支持。
Q39: magicmind对大部分的网络都支持吗?或者说 使用了magicmind 是不是基本都可以比用cnnl推理更快?
A39: 是的,支持大部分经典的网络。是的,一般都比CNNL推理更快。
Q40: GPU上训练推理的model 转换到MLU上需要改动哪些工具?
A40: 星空体育的软件栈自带相关的工具。
热门帖子
精华帖子







 Ashelly
13 回复
Ashelly
13 回复
 fengyunkai
1 回复
fengyunkai
1 回复

 goodchong
goodchong jyjyjyjyjy
jyjyjyjyjy Github
Github 开发平台
开发平台 文档中心
文档中心 新手必读
新手必读